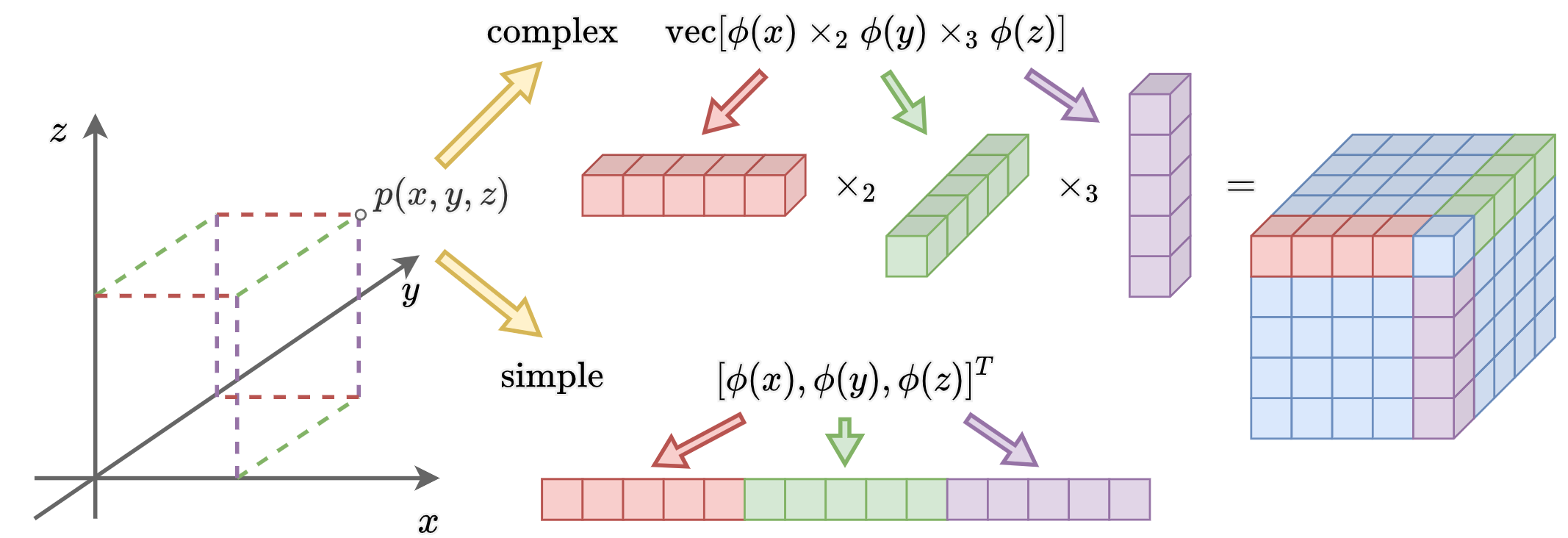
Illustration of different methods to extend 1D encoding of length K to
N-dimensional case.
Simple encoding is the widely used method currently, which is only the concatenation of encodings in each dimension
to get a NK size encoding. We propose an alternative encoding method:
conduct mode-n product to get the N dimensional cube,
which we define as the complex encoding.
Abstract
It is well noted that coordinate-based MLPs benefit---in terms of preserving high-frequency information---
through the encoding of coordinate positions as an array of Fourier features.
Hitherto, the rationale for the effectiveness of these positional encodings has been mainly studied
through a Fourier lens. In this paper, we strive to broaden this understanding by showing that alternative
non-Fourier embedding functions can indeed be used for positional encoding. Moreover, we show that their
performance is entirely determined by a trade-off between the stable rank of the embedded matrix and the
distance preservation between embedded coordinates. We further establish that the now ubiquitous Fourier
feature mapping of position is a special case that fulfills these conditions.
Consequently, we present a more general theory to analyze positional encoding in terms of shifted basis functions.
In addition, we argue that employing a more complex positional encoding---that scales exponentially with the
number of modes---requires only a linear (rather than deep) coordinate function to achieve comparable performance.
Counter-intuitively, we demonstrate that trading positional embedding complexity for network deepness is
orders of magnitude faster than current state-of-the-art; despite the additional embedding complexity.
To this end, we develop the necessary theoretical formulae and empirically verify that
our theoretical claims hold in practice.
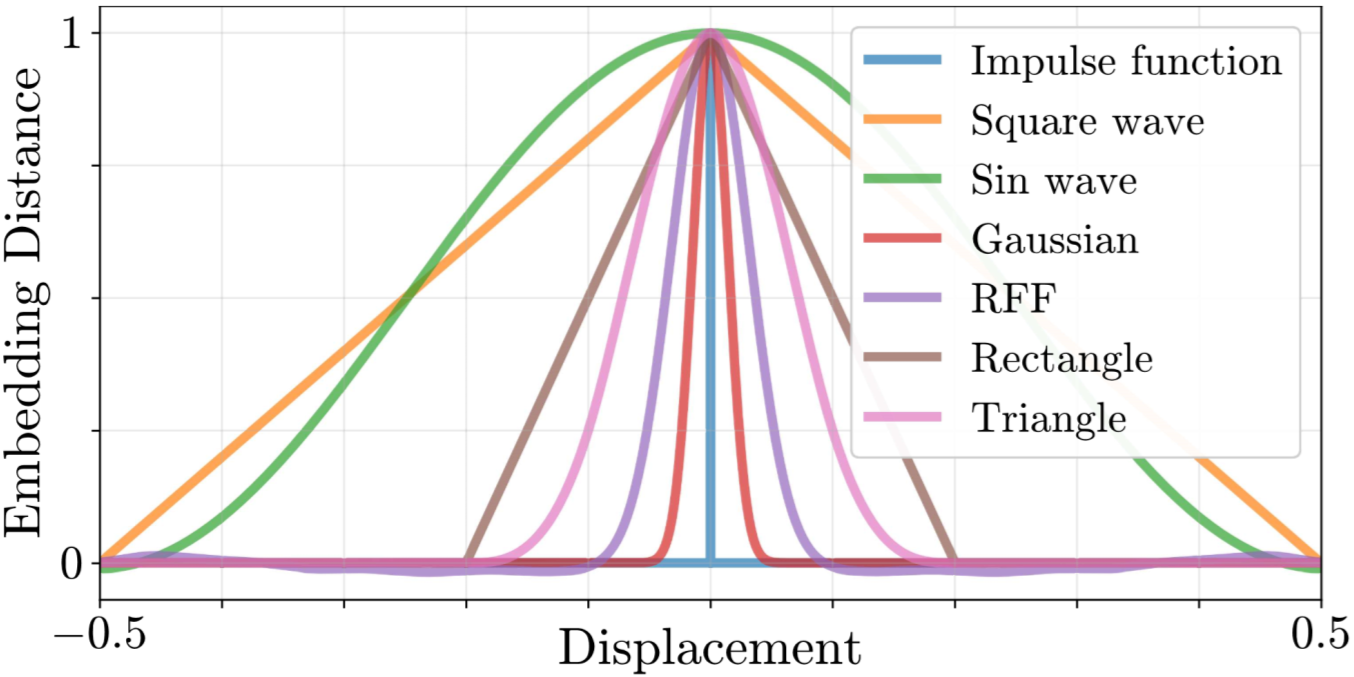
Stable rank and the distance preservation of the embeddings
Quantitative comparison of the stable rank (left figure) and the distance preservation (right figure)
of different embedders and RFFs.
As expected, the stable rank of the impulse embedder strictly increases with the number of sampled points,
causing poor distance preservation. The stable rank of the sine
embedder is upper-bounded at 2.
The stable ranks of the square embedder and the
sine embedder almost overlap.
However, if the sample numbers are extremely high (not shown in the figure), their stable ranks begin to deviate.
Similarly, the square embedder demonstrates perfect distance preservation,
and the sine embedder is a close competitor. In contrast,
the Gaussian embedder and the RFF
showcase mid-range upper bounds for the stable rank and adequate distance preservation,
advocating a much better trade-off between memorization and generalization.
3D: video reconstruction (separable coordinates)
We provide a reconstruction results for 2 videos using separable coordinates (regular-grid sampled training points)
with different combinations fo simple or complex encodings and network depths.
Complex encodings with only one single linear layer (without hidden non-linear layers) have comparable performance
to simple encodings with deep non-linear MLPs (5 layer MLPs).
Complex shifted encodings outperformed complex Fourier feature-based encodings.
Simple, depth 0
Simple, Depth 4
Complex, Depth 0
Complex, Depth 1
LinF
LogF
RFF
Tri
Gau
Simple, depth 0
Simple, Depth 4
Complex, Depth 0
Complex, Depth 1
LinF
LogF
RFF
Tri
Gau
3D: video reconstruction (non-separable coordinates)
We provide a reconstruction results for 2 videos using non-separable coordinates (randomly sampled training points)
with different combinations fo simple or complex encodings and network depths.
Complex encodings with only one single linear layer (without hidden non-linear layers) have comparable performance
to simple encodings with deep non-linear MLPs (5 layer MLPs).
Complex shifted encodings outperformed complex Fourier feature-based encodings.
Simple, depth 0
Simple, Depth 4
Complex, Depth 0
Complex, Depth 1
LinF
LogF
RFF
Tri
Gau
Simple, depth 0
Simple, Depth 4
Complex, Depth 0
Complex, Depth 1
LinF
LogF
RFF
Tri
Gau
2D: image reconstruction (separable coordinates)
We provide a reconstruction results for 2 images (an archway and a heap of walnuts) using separable coordinates
(regular-grid sampled training points) with different combinations fo simple or complex encodings and network depths.
Complex encodings with only one single linear layer (without hidden non-linear layers) have comparable performance
to simple encodings with deep non-linear MLPs (5 layer MLPs).
Complex shifted encodings outperformed complex Fourier feature-based encodings.
We provide a reconstruction results for 2 images (a lion and a seaside residential area) using
non-separable coordinates (randomly sampled training points)
with different combinations fo simple or complex encodings and network depths.
Complex encodings with only one single linear layer (without hidden non-linear layers) have comparable performance
to simple encodings with deep non-linear MLPs (5 layer MLPs).
Complex shifted encodings outperformed complex Fourier feature-based encodings.
Ground truth
Simple, depth 0
Simple, Depth 4
Complex, Depth 0
Complex, Depth 1
LinF
LogF
RFF
Tri
Gau
Ground truth
Simple, depth 0
Simple, Depth 4
Complex, Depth 0
Complex, Depth 1
LinF
LogF
RFF
Tri
Gau
Citation
@article{zheng2022trading,
title={Trading Positional Complexity vs. Deepness in Coordinate Networks},
author={Zheng, Jianqiao and Ramasinghe, Sameera and Li, Xueqian and Lucey, Simon},
journal={Proceedings of the European Conference on Computer Vision (ECCV)},
year={2022}
}